03 - Decision Trees
Decision tree
Tree with the following characteristics:
- each internal node tests an attribute
- each branch is a value of an attribute
- each leaf node assigns a classification value

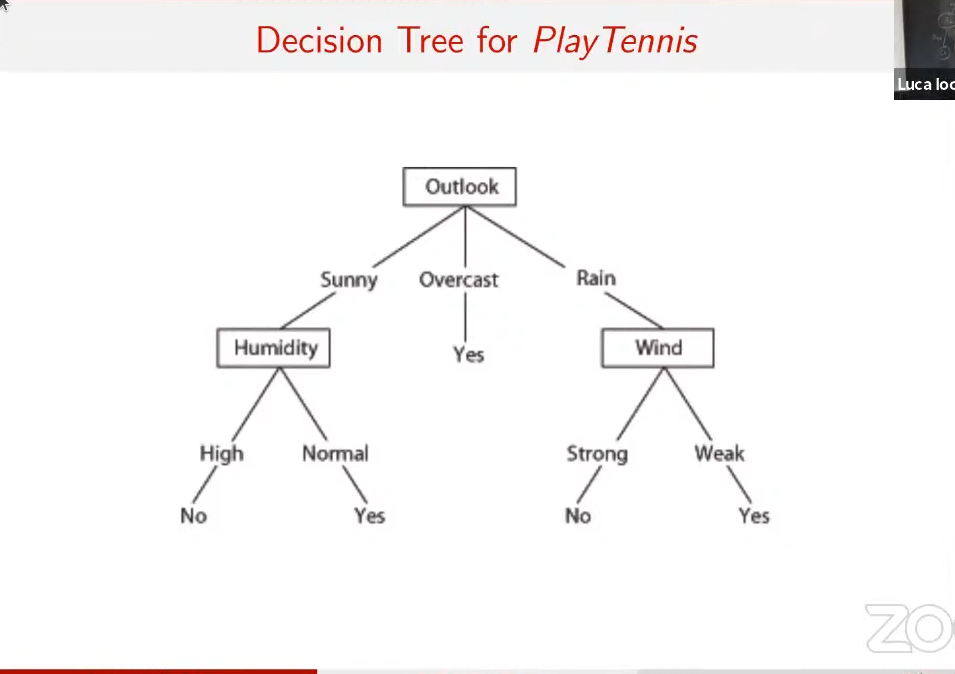
- a classic decision tree, like the ones in Algorithms
How to form a rule
- evaluates the branches we are interested in and put them in disjunction
- for example: IF (Outlook = Sunny) AND (Humidity = High) THEN PlayTennis = No
ID3 Algorithm
We have: INPUT: Examples (both positives and negatives), Target Attribute (Play Tennis), Attributes (Outlook, Wind…) OUTPUT: DT (Decison Tree)
We have three cases if attributes are empty:
- Examples contains only positives: RETURN +
- Examples contains only negatives: RETURN -
- Both of them: + or -, depending on majority samples in D
(also called GENERAL CASE) We have these cases if attributes are NOT empty:
- let’s choose a specific attribute (by using a specific criteria)
- let’s create a node
- let’s create a child node
- let’s make a recursive call to build all the subsets
- each recursive call will change the examples and the attributes EXCEPT the one I am already considering
An example is worth one thousand words:

Entropy and Information gain
it represents the impurity or randomness in a dataset
Information Gain measures the effectiveness of a feature in classifying a dataset. It quantifies how much information a feature provides about the class label. High information gain means a feature is very useful for classification.
To calculate information gain for a feature A with respect to a dataset S, you compute the entropy of the original dataset Entropy(S), and then calculate the weighted sum of entropies after splitting the dataset based on feature A.
Example
Let’s consider a simple binary classification problem to illustrate how entropy and information gain are used in decision tree classification.
Suppose we have a dataset of emails that are classified as either spam (positive class) or non-spam (negative class). The dataset has two features:
- Feature 1: Whether the email contains the word “lottery” (binary feature: 1 if yes, 0 if no).
- Feature 2: Whether the email contains the word “discount” (binary feature: 1 if yes, 0 if no).
Let’s calculate entropy and information gain to decide the best feature for the first split in the decision tree.
Calculating Entropy for the Initial Dataset:
Let’s assume there are 60 emails in the dataset, with 30 being spam and 30 non-spam.
Calculating Information Gain for Feature 1 (“lottery”):
Let’s assume 20 emails have the word “lottery” and 40 do not.
Calculating Information Gain for Feature 2 (“discount”):
Let’s assume 25 emails have the word “discount” and 35 do not. In this example, Feature 2 (“discount”) has a higher information gain compared to Feature 1 (“lottery”). Therefore, the decision tree would choose “discount” as the first split, as it provides more information in reducing the uncertainty about the class labels.
So, entropy measures how mixed up things are, and information gain helps us figure out the best way to organize and understand the mix!
When the entropy is 0 all the subsets are such that in each subset there only are positives or negatives example!
ID3 for short
- Create a rotto node
- if all examples are pos, return Root with label +
- if all examples are neg, return Root with label -
- if attributes is empty, then return the node root with label = most common value of target_attribute in Examples
- otherwise
- A ← the best decision attribute for Examples
- assign A as devision attribute for Root
- for each value of A
- add a new branch from Root corresponding to the test A =
- = subset of Examples that have value for A
- if is empty then add a leaf node with label = most common value of target_attribute in examples
- else add the tree ID3(, Target_attribute, Attributes-{A})
- for each value of A
Avoid overfitting
- stop growing when data split not efficient
- grow full tree then post prune In pratica semplifichi un nodo mettendo al posto di un albero di decisione, un certo valore o meno.
GOOGLE COLAB HERE!