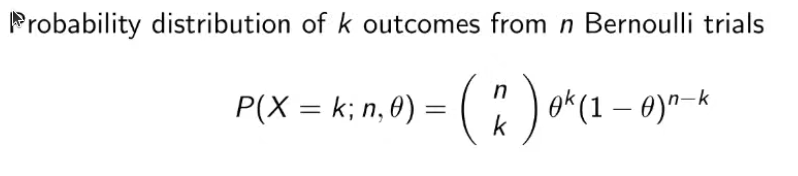05 - Bayesan Learning
Overview
- Description:: define a ML in terms of distribution, probabilistic approach
Probabilistic estimation
Given D and H: P(H|D): we know the dataset and want to estimate the probability of an hypothesis
This is called posterior probability: it is the probability of h after we see the data.
P(h) = prior probability of hypotesis h P(D) = prior probability of training data D P(h|D) = prob of h given D P(D|h) = prob of D given h
MAP Hypothesis
Given any function, the argmax is the highest point a function reaches on the x axe.
Maximum a posteriori hypotesis
We don’t need to divide for P(D) because it is a constant!
- assuming that if the hypothesis are a priori uniformly distributed
Maximum Likelihood (ML)
Important
When we have information about priors, we use MAP Hypothesis, if we can assume that all hypothesis have uniform priori distribution we can use ML Hypothesis
- example
- h1, h2, h3
- P(h1|D) = 0.4
- P(h2|D) = 0.3
- P(h3|D) = 0.3
- given a new istance
- h1(x) = +
- h2(x) = -
- h3(x) = -
- h1, h2, h3
If we consider HMAP it will predict + But if we use the contribution of all hypothesis then the negative prediction is better in terms of result.
So it is not convenient HMAP
Bayes Optimal Classifier
Consider target fn f: X → V, V={v1, …, vk}, Dataset D,
total probability over H
The best prediction for x will be the argmax of this
Optimal means that it optimally solves the problem we stated at the beginning.
It is a theoretical model, that unfortunately cannot really be applied unless we have a very small cases.
Example
- 10% are h1: 100% cherry
- 20% are h2: 75% cherry, 25% lime
- 40% are h3: 50% cherry, 50% lime
- 20% are h4: 25% cherry, 75% lime
- 10% are h5: 100% lime
We choose a random bag (we dont know the type) and extract some candies from it. What kind of bag is it? What is the probability of extracting a candy of a specific flavor next?
Ok, now we must find prior probab distribution: 0.1, 0.2, 0.4, 0.2, 0.1
Likelihood for lime candy (probability of dataset given hypothesis): P(I|H) = 0, 0.25, 0.5, 0.75, 1
Applying the formula to extract a lime candy: Now we don’t have any dataset, so dataset is empty.
Let’s assume we get a lime candy.
We want to compute the probability distribution of the hypothesis given this dataset:

The usual thing, but is known as “normalization factor”.
How to calculate alpha?
Same goes for the second candy:
 The blue arrow: we computed that in the previous step
The red segment: is only the usual thing to multiply
The blue arrow: we computed that in the previous step
The red segment: is only the usual thing to multiply
Same goes for the third candy? If we consider the approach of and it is H5 in this case, it would be 1. It is not correct!
So, we compute the sum of the probabilities to extract lime among all the possible hypothesis.
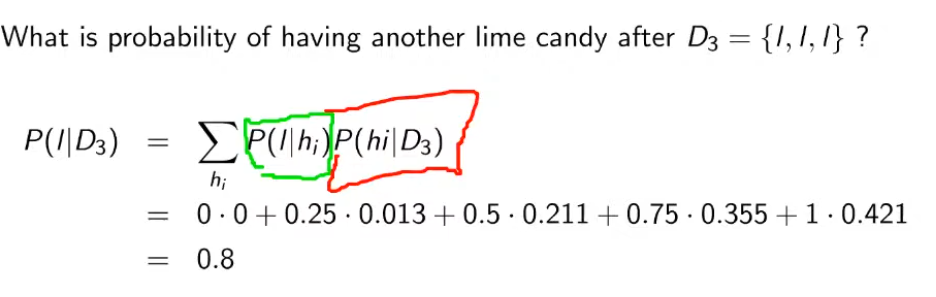 (we don’t count the first, because is 0!)
(we don’t count the first, because is 0!)
Bernoulli distribution
The Bernoulli distribution is a discrete probability distribution representing two possible outcomes - often referred to as success and failure.
Imagine you are tossing a fair coin. The outcome can be either heads (success) or tails (failure). This situation perfectly fits the Bernoulli distribution because there are only two possible outcomes, and each outcome has a fixed probability.
For example, if the coin is biased and the probability of getting a head (p) is 0.7 (and hence the probability of getting a tail is 1−p=0.31−p=0.3), the PMF for this unfair coin would be:
In this case, the probability of getting heads (P(X=1)P(X=1)) is 0.7, and the probability of getting tails (P(X=0)P(X=0)) is 0.3.
General approach

More Bernoulli (ex. coins)