09 - GPUs TPUs
Overview
- Description:: How does storage work in a large-scale datacenter
GPUs
- from ‘10 to ‘20 GPU usage has increased
- CPUs vs GPUs: - the CPUs have cores and a lot of caches - the latter ones have much more cores, at the cost of simpler/smaller caches and control units - program few threads → CPUs, many threads → GPUs
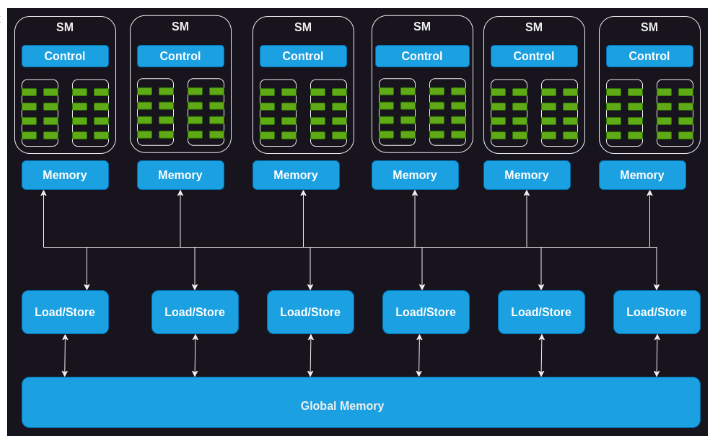
- array of streaming multiprocessors
- each of them: multiple cores with shared control logic and instruction cache
- they can also have other modules (e.g. raytracing)
- shared global memory
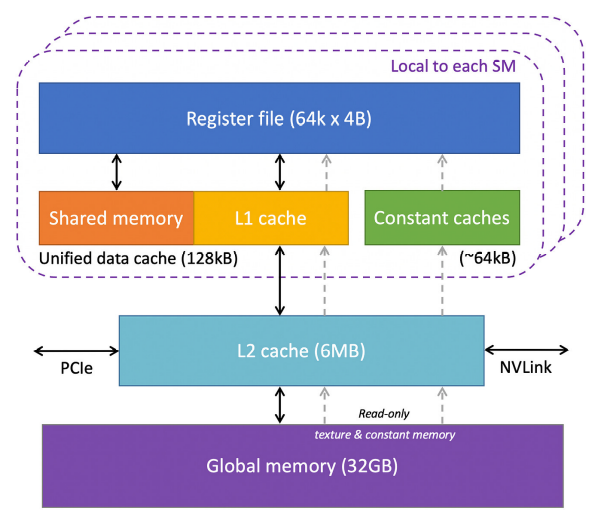
- they are built on the classic von Neumann architecture, that it is not performance-oriented (other models are better)
Programming a GPU
Several options can be used:
- C++
- directive-based languages (openMP)
- frameworks that abstract the hardware away (Kokkos)
- native libraries (OpenCL)
- native code (CUDA)
CUDA
- is the most used and most optimized
- threads are divided in thread blocks, multiple thread blocks from a grid
- instructions used to be copied back and forth central memory to GPU, but now they have a common shared area
- one big challenge is how to connect multiple GPUs each other
TPUs
- similar tp GPUs but they use tensors, a multidimensional array structure
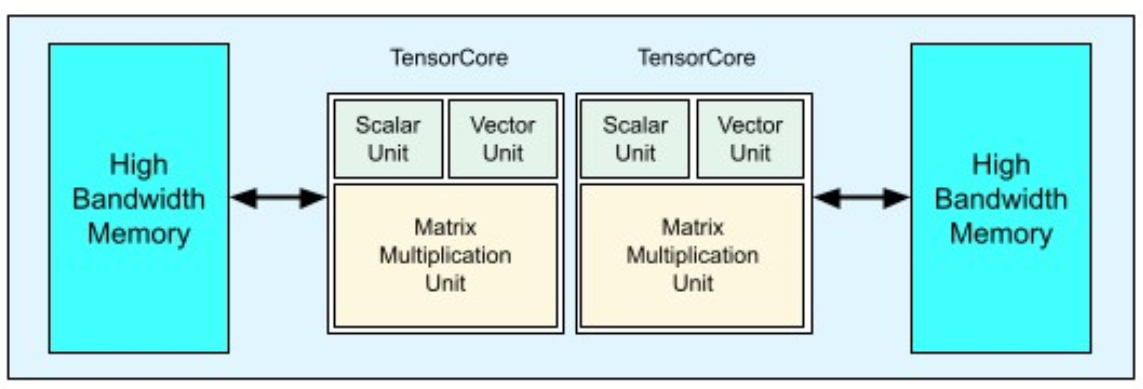
- Key feature is the Matrix Multiplication Unit
- best way to connect them: torus
- performance high, cost low if compared with classic GPUs